 Je soutiens l'X
Je soutiens l'X - Accueil
- Actualités
- Sommet de L’IA : Vers Une Intelligence Artificielle Digne de Confiance
Sommet de l’IA : Vers une intelligence artificielle digne de confiance

Les participants à ce symposium étaient Aymeric Dieuleveut, professeur à l’École polytechnique et chercheur au Centre de mathématiques appliquées (CMAP*), Dame Wendy Hall, professeure d’informatique à l’université de Southampton, Jean-Michel Loubes, directeur de recherche à Inria, Moritz Hardt, directeur à l’Institut Max Planck pour les systèmes intelligents et Michael Krajecki, directeur de recherche à l’Agence ministérielle de l’intelligence artificielle de défense (AMIAD). La session a été animée par Florence D’Alché-Buc, professeure à Télécom Paris (Institut Polytechnique de Paris).
Les usages de l’IA se multiplient, parfois pour le meilleur, mais avec des risques importants. Parmi les conséquences sociales néfastes, il est aujourd’hui bien documenté que les IA peuvent être biaisées, c’est-à-dire que leur résultat est influencé systématiquement (et non accidentellement). Jean-Michel Loubes a donné l’exemple d’un algorithme permettant de faire des recommandations d’emplois à partir d’un jeu de données contenant des éléments biographiques. En changeant simplement les pronoms masculins en pronoms féminins, les recommandations passent de « chirurgiens » à « infirmières ». Ces biais peuvent constituer des atteintes aux droits fondamentaux (discrimination de genre, discrimination raciale, …) ou entraîner des conséquences dans l’industrie ou sur l’économie. Par exemple, un algorithme sur un site de vente peut favoriser systématiquement certains vendeurs. Les biais proviennent du jeu de données lui-même qui a été utilisé pour « entraîner » l’IA, ou bien de l’algorithme.
Lutter contre les biais
Outre les biais, les décisions automatiques ont d’autres conséquences, comme les prophéties auto-réalisatrices. Moritz Hardt l’a illustré avec la plateforme Youtube qui utilise l’IA pour déterminer quelles vidéos recommander à un utilisateur, en estimant le temps que celui-ci restera devant. Il y a un effet de prophétie auto-réalisatrice, car les utilisateurs auront effectivement tendance à cliquer sur la première vidéo recommandée, et donc à passer du temps dessus, rendant la prédiction d’autant plus « vraie ». L’effet inverse, de prophétie auto-négative, existe aussi, par exemple lorsque la prédiction des itinéraires pour éviter les embouteillages entraîne un afflux trop important sur l’itinéraire proposé. Autrement dit, le fait de prédire quelque chose change la valeur de ce qu’on essaie de prédire. Les IA ont donc un effet d’influence, d’autant plus important que la plateforme est puissante. Dans ce cas, comme dans celui des biais, il convient de développer des outils mathématiques pour mesurer ces effets et s’en prémunir. Mais l’enjeu de leur atténuation ne concerne pas que la recherche.
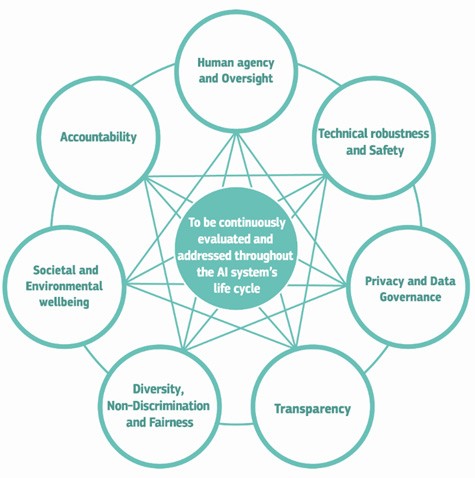
L’Union européenne a adopté des recommandations et des réglementations sur l’IA, en particulier l’AI act en 2024, comme l’a rappelé Michael Krajecki. Ce texte vise à réguler les systèmes commercialisés sur le marché européen. Il définit notamment une liste d'applications de l'IA à risque, dont les systèmes de recommandation de candidats à un emploi font par exemple partie. L’AI act établit des responsabilités : les concepteurs du modèle doivent prouver qu'il est conforme, mais les entreprises qui achètent et déploient un algorithme conçu par un tiers sont également responsables.
Un enjeu technique et social
Parmi les exigences pour une IA digne de confiance se trouve le respect de la confidentialité des données privées. Pour autant, il peut nous être utile que certains algorithmes soient entrainés sur une partie de nos données. Plutôt que de céder ces données à un tiers pour que celui-ci entraîne un système d’IA, un nouveau paradigme est apparu ces dix dernières années, l’apprentissage fédéré, comme l’a détaillé Aymeric Dieuleveut dans son exposé. Dans ce cas, les données restent stockées localement chez l’utilisateur. Ce type d’apprentissage est déjà implémenté pour quelques applications, comme lorsque nos smartphones proposent le prochain mot à taper pour un SMS. Aymeric Dieuleveut a présenté les travaux de son équipe à l’École polytechnique sur des architectures décentralisées, et comment elles pourraient résister à un acteur qui perturberait l’apprentissage.
Au-delà des aspects techniques, la nécessité que l’IA soit digne de confiance est un enjeu de société, a souligné Dame Wendy Hall. Qui établit comment l’IA doit être fiable, et pour qui elle doit être fiable ? La réponse dépend des contextes sociaux et politiques. A l’échelle mondiale, il est crucial d’avoir un dialogue à ce sujet, comme essaie de le faire l’ONU avec le United Nations AI Advisory Body. Les intervenants ont insisté sur l’importance de soutenir la recherche académique, et son indépendance, ainsi que la dimension interdisciplinaire nécessaire entre mathématiques, informatique et sciences sociales.
*CMAP : une unité mixte de recherche CNRS, Inria, École polytechnique, Institut Polytechnique de Paris, 91120 Palaiseau, France